Technical Report
Creatify Agent: a closed-loop multi-agent system for video and image ad creatives
Abstract
Creatify Agent is a closed-loop multi-agent system purpose-built for video and image advertising. From a single creative brief — often only a product URL or a brand reference — the agent plans the spot, dispatches each scene to a generation backend it selects per shot, scores the audio, composites the typography, and verifies the result against the brief before delivering a finished, brand-faithful ad. The same closed-loop architecture produces image creatives, planning the composition, selecting a per-asset generation backend, and verifying the output against the brief. The system is structurally different from the two adjacent classes of tool it is most often compared with: a foundation text-to-video model that produces a single short clip from a prompt, and a general-purpose video agent that wraps a single model behind a conversational UI. This report describes the architecture, presents VideoAdAgent Bench v1 — the first public benchmark for AI ad-video production — and reports the headline result: Creatify Agent outperforms general-purpose video agents and frontier text-to-video models on the composite, hallucination, and pairwise-preference metrics that govern whether a finished ad is shippable.
1 Introduction
A performance ad creative — video or image — is structurally different from the output a frontier generative model produces. A video ad is a 15-to-60-second multi-shot deliverable with a hook, body beats, a product moment, scored audio, on-brand typography, and a call-to-action. A foundation T2V model — Veo 3.1, Kling 3.0, Seedance 2.0, Sora 2 — renders one shot at high visual fidelity, with no representation for a multi-scene plan, no verification of brand state across cuts, no audio scored to a cut cadence, and no typography layer. A general-purpose video agent wraps such a model behind a conversational interface but inherits the same gap: it adds a chat surface, not the ads-specialized verification layer that determines whether a finished ad is shippable.
Creatify Agent is neither class of system. It is an orchestration layer that takes a brand-and-brief as input and dispatches the work across whichever generation models, retrieval steps, audio services, and verification passes the brief requires. It selects models per scene rather than being one. It maintains typed state — brand colors, product facts, persona identity, required on-screen text — across the production and verifies each scene against that state before delivery rather than trusting the generator's first output. Recent agent-systems research (Mora, VISTA, VideoReward) has converged on the conclusion that multi-agent decomposition with an in-the-loop critic outperforms single-model generation on every dimension that governs a finished deliverable; Creatify Agent is an instantiation of that direction specialized end-to-end for advertising and evaluated against the rest of the field on the benchmark introduced in §3.
2 System design
Our agent works as a closed loop of specialized sub-agents. A producer ingests the brief, derives a scene plan, and emits a typed asset graph: product facts, persona descriptors, brand state, required on-screen text. Directors translate scene specs into generation calls, choosing models and parameters per shot. A critic evaluates each rendered scene against the asset graph along an explicit rubric and either approves it or returns it to the director with a structured verdict, so a scene that fails on fidelity is regenerated locally rather than triggering a whole-ad re-roll. The loop closes after delivery: every shipped ad is graded, every defect becomes a regression case, and the rubric tightens with each production.
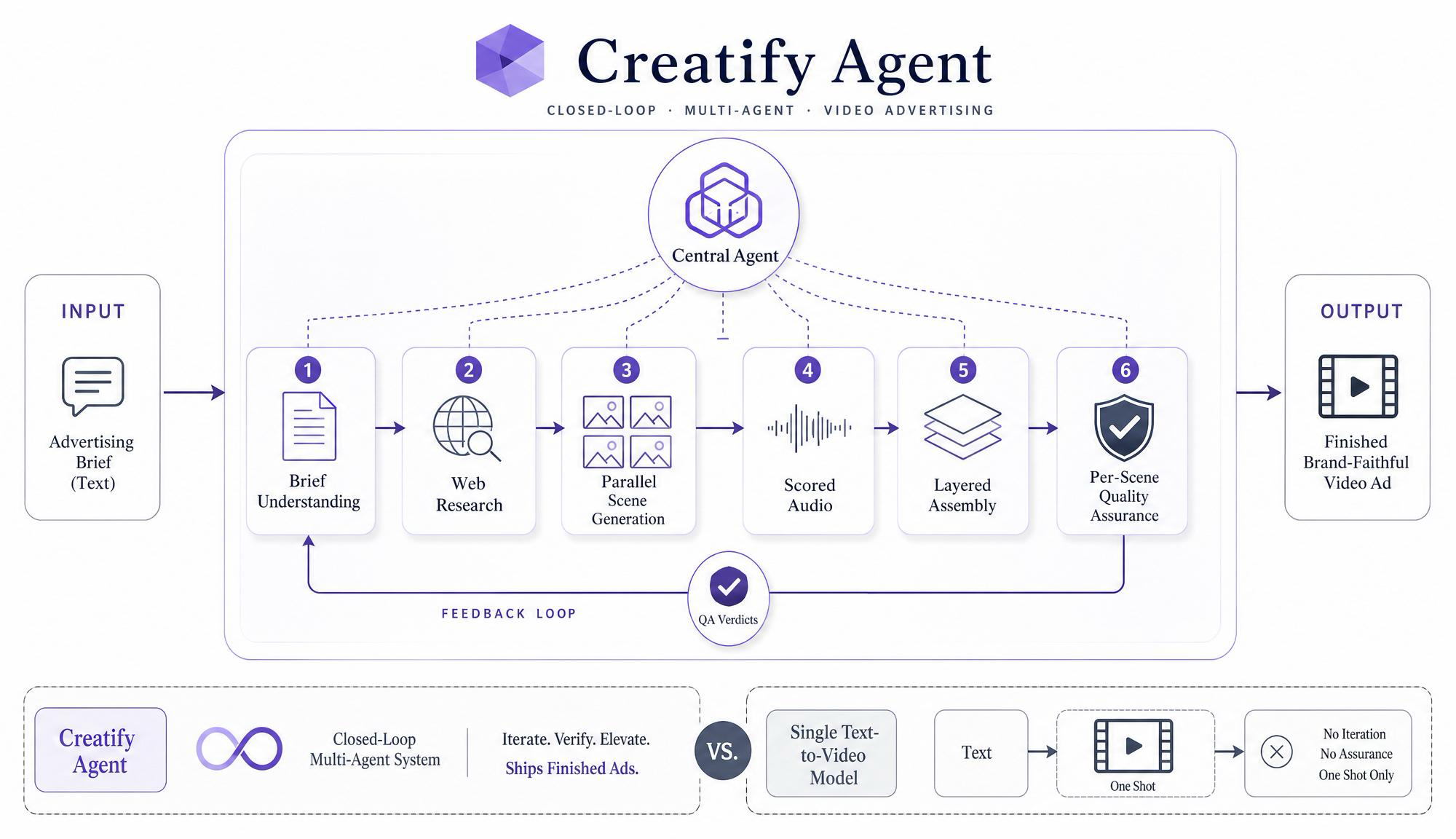
Figure 1. Creatify Agent (top): a central producer orchestrates six stages — brief understanding, web research, parallel scene generation, scored audio, layered assembly, and per-scene QA — with the critic's verdicts feeding back into the loop. Versus a single text-to-video model (bottom right): one shot, no iteration, no verification.
2.1 Creative research and reference-anchored generation
The producer can ground a brief in real creative context before any scene is rendered. The user can ask the agent to run a creative search — calling TikTok and Instagram for 8–10 high-performing ads in the brand's category, returned with engagement metadata and hook decomposition — and then feed the resulting formats back as reference input for the storyboard, so identifying what's working in the category becomes a first-class step the user can request rather than a separate research project. Two further modalities ground the brief the same way. A URL (for example omakai.com) is fetched and parsed for brand identity — name, concept, palette, hero imagery — so a user with no uploaded asset library still produces a brand-faithful spot. A reference video — a viral TikTok, a competitor spot, an existing brand reel — is decomposed into its working ingredients (shot rhythm, color and lighting, camera language, transition style, on-screen-text cadence) which then ground the scene plan. None of these modalities is available to a foundation T2V model or a general-purpose video agent: a URL is a string of characters to them, a reference video is unsupported, and trending creative context lives outside their training cutoff.
2.2 Persistent brand memory
The agent maintains a structured memory across sessions, keyed per user and per brand. Product facts (price points, hero features, do-not-show items), brand voice and color palette, persona preferences, and successful past creative directions are retained automatically; an end-of-session distillation step proposes durable facts worth keeping. The second time a user asks for an ad for the same brand, the agent does not require re-uploading the brand kit, re-explaining the price point, or re-picking the voice. Every text-to-video model and every general-purpose video agent we benchmarked starts from zero on every call.
2.3 Pluggable skills and multi-output expansion
Production skills are pluggable. A single producer can deliver a creator-led UGC spot, a glossy product demo, a persona-anchored testimonial (built on Aurora, Creatify's in-house avatar model), a kinetic-typography motion-design reel, or a competitor-research-grounded comparison ad, from the same brief format. The structured asset graph also admits low-marginal-cost multi-output expansion from a single brief — alternate hooks, alternate personas, alternate aspect ratios — without re-rolling the whole production, since individual axes can be mutated independently.
2.4 Audio scoring
Audio is generated and timed as a first-class production element rather than muxed in as an afterthought. A music track is generated to the cut cadence; voiceover is rendered separately from a TTS layer with brand-appropriate tone and pacing; both are composited at known offsets onto the video and typography layers. Every Creatify variant in the benchmark ships with scored audio; every raw text-to-video baseline ships silent; HeyGen V3 ships with avatar narration only. Audio quality is one of the dimensions the no-brief Arm 3 judges score most strongly, which partly explains the cleanness of the Arm 3 separation.
2.5 In-the-loop hallucination control
The critic is a vision-capable model run inside the production loop, not a post-hoc filter. Each scene is judged against the typed asset graph along an explicit rubric — product fidelity, object hallucination, text quality, physical violations, anatomy, overall quality — and failures route back with a structured verdict (which dimension, by how much, on which frame) for regeneration with that feedback inlined. The rubric and thresholds are human-readable rules the team can tighten, not opaque model weights — a design choice articulated in recent agent-systems work on harness-as-optimization-target (Lee, Khattab, Finn et al.) and critique-and-revise loops over explicit policies (Weng). The critic runs on an in-house vision stack specialized for ad failure modes — brand-mark drift, mis-rendered product labels, garbled CTAs, cross-cut continuity breaks. The benchmark result is the lowest frame-level hallucination score in the field: Creatify Agent Pro at 1.90 (the only score below 2.0), Lite at 2.85, both below the production-grade FAIL threshold of 3.0; every raw T2V baseline scores 3.65–3.85, and HeyGen V3 scores 4.40.
3 Benchmark
Existing video-quality benchmarks (VBench, VBench-2.0, video-arena pairwise leaderboards) measure per-frame fidelity on raw text-to-video models; none measures whether the output functions as an ad along the axes that govern shippability — hook strength, brand fidelity, CTA clarity, ad effectiveness, hallucination cost, production polish. VideoAdAgent Bench v1 is built to fill that gap; the full leaderboard, judging artifacts, and rerun scripts are public at the bench page.
3.1 Brief set
The benchmark covers every major performance-ad pattern — problem-solution, before-after, product demo, testimonial, lifestyle — plus stress tests targeting the hardest axes of multi-scene production (anchor storytelling, persona consistency, brand-asset reuse, structured CTA text, persuasion-arc compliance). Each brief is a structured object (product, intent, format, constraints, input assets) using fictional brands and AI-generated product mocks to avoid real-customer IP and PII. The full set is pre-registered to a tagged commit before any system generates output, so no system can be tuned to the specific briefs.
3.2 Evaluation protocol
The benchmark separates three orthogonal questions across three independent pairwise-judging arms. Every pair is judged by two vision-capable LLM judges (Claude Opus 4.7 + GPT-5) twice with positions swapped to control for left-vs-right bias; a verdict counts only when a judge agrees with itself across the swap, and both judges must agree for a consensus verdict.
| Arm | Question | Pairs | Headline metric |
|---|---|---|---|
| Arm 1 — Capability | Is the agent better than other agentic video systems? | Creatify vs every general-purpose video agent (HeyGen V3, Luma). Judges see the brief. | Win-rate against the agentic field. |
| Arm 2 — Ad Quality | Is the agent better than the strongest raw T2V models? | Creatify vs Veo 3.1, Kling 3.0, Seedance 2.0. Two baseline configurations per model: single-scene (default API call — one prompt, one 8–12 s clip) and multi-scene (planned per-scene prompts, stitched). Judges see the brief and score eight ad-quality dimensions; the headline table reports the multi-scene configuration. | Overall preference (0–1). |
| Arm 3 — Video Production Quality | Is the output a higher-quality deliverable, ignoring the brief? | Same pairs as Arm 2 but judges do not see the brief. A frame-level hallucination rubric is folded in at 3× weight against structural compliance. | Video-quality score (0–1). |
The composite reported on the leaderboard is a blend of Arm 2 (ad quality) and Arm 3 (production quality), so a system must perform on both axes to climb. A frame-level hallucination score (0–10, lower is better; ≥ 3.0 is a production-grade FAIL) is folded into Arm 3 and published as a separate column on the leaderboard.
4 Results
The composite ranks Creatify Agent first in the field; both production-shipping variants outscore every general-purpose video agent and every raw T2V baseline on every aggregate metric. All systems — Creatify and every competitor — are graded under one-shot conditions: a single brief in, a single ad out, no feedback turn. Creatify Agent's production deployment is conversational and supports surgical per-scene revisions; the bench deliberately strips that capability to keep the comparison fair against single-shot models, which means the production experience exceeds the numbers reported here.
| Rank | System | Composite | Arm 1 | Arm 2 | Arm 3 | Hallucination ↓ |
|---|---|---|---|---|---|---|
| 1 | Creatify Agent · Pro | 0.901 | 0.732 | 0.775 | 0.855 | 1.90 |
| 2 | Creatify Agent · Lite | 0.836 | 0.716 | 0.757 | 0.778 | 2.85 |
| 3 | Luma Agent | 0.585 | 0.580 | 0.603 | 0.741 | 3.20 |
| 4 | HeyGen V3 Agent | 0.327 | 0.358 | 0.378 | 0.609 | 4.40 |
| 5 | Seedance 2.0 (multi-scene) | 0.312 | — | 0.337 | 0.588 | 3.65 |
| 6 | Kling 3.0 (multi-scene) | 0.301 | — | 0.365 | 0.585 | 3.80 |
| 7 | Veo 3.1 (multi-scene) | 0.287 | — | 0.362 | 0.549 | 3.85 |
Table 1. Top-of-field placements: Creatify Agent Pro by 0.32 points over the strongest general-purpose video agent and 0.59 over the strongest raw T2V baseline; Lite by 0.25 and 0.52 respectively. Scores are 0–1, higher is better, except hallucination (0–10, lower is better). Arm 1 is "—" for raw T2V systems, which do not compete in the agent-vs-agent arm. Pro wins 87% of consensus pairwise verdicts against the agentic field and 95% against the raw T2V baselines.
5 Case studies
Three real production-app outputs run from the same prompt against the strongest commercial alternatives (one foundation T2V model, one general-purpose video agent). Not curated for the report. Each case exposes a different agent capability — brief decomposition, brand-asset grounding, web research — with no single-shot equivalent.
5.1 Multi-shot cooking ad
20-second TikTok cooking ad, ~50 cuts at ~0.4s each. Compared against Veo 3.1 (single-shot T2V) and HeyGen V3 (general-purpose video agent).
The producer parses the prompt as a shot list, decomposes it into ~50 cuts dispatched to per-scene directors in parallel, and scores audio to the cut cadence. Veo 3.1's API has no parameter for total duration or multi-shot structure (max single-call duration 8 s, output one take). HeyGen V3 interprets the prompt as narration content for its avatar rather than as a shot specification.
5.2 Brand-image-anchored Instagram ad
User uploads a TopStep brand reference image and asks for a hiker-summit Instagram ad. Compared against Veo 3.1 image-to-video (brand image as starting frame) and HeyGen V3 (prompt-only — no image input).
The reference image is admitted to the typed asset graph and anchors every scene: brand colors persist, the brand mark is rendered as a verified typography layer at the end card, the hiker character holds across the setup→struggle→summit arc. Veo 3.1 preserves the starting frame inside one 8-second take but has no multi-scene-arc representation. HeyGen V3's API accepts only a prompt string, so the brand image is not used.
5.3 URL-only brief, no uploaded assets
User pastes one URL; the agent fetches the site, extracts brand identity, and writes its own brief. Neither baseline can call out to the web.
OMAKAI is a Miami omakase sushi restaurant. The producer's web-retrieval step fetches omakai.com, extracts brand name, omakase concept, and Miami positioning, then grounds the storyboard before any generation call. Neither baseline has web retrieval: Veo 3.1 produces visually competent but topically generic restaurant footage from the prompt string; HeyGen V3 narrates the URL itself as the voice line. URL-only briefs are the dominant SMB-onboarding case in the production app.
6 Limitations
Hallucination is low but not zero. Both Creatify variants clear the production-grade hallucination threshold (Pro at 1.90, Lite at 2.85), but a small share of Pro-generated ads still contain a minor brand-text wobble or a subtle inter-cut inconsistency the critic missed. Driving that residual toward zero is an active research direction.
One-shot evaluation only. The benchmark grades a single brief in, a single ad out, with no feedback turn. The production agent is conversational; a user who flags a residual defect ("the price on scene 3 is wrong") triggers a surgical per-scene re-generation with the correction inlined. The hallucination rate achievable through interactive feedback is materially lower than the one-shot number reported here and is not studied in this report.
7 Reproducibility
Every claim in this report can be reproduced from the public benchmark, released as open source alongside this launch at github.com/creatify-ai/VABench. Brief set, schemas, judge prompts, scoring rubrics, runner scaffolds, and aggregation scripts are all included. The brief set was pre-registered to a tagged commit before any system generated output, so no system in the benchmark could have been tuned to the specific briefs.
8 Related work
- Multi-agent video generation: Mora, VideoDirectorGPT, FilmAgent, StoryAgent, VISTA.
- Video-quality benchmarks: VBench / VBench-2.0; VideoGen-Eval; Artificial Analysis Video Arena for pairwise position-bias control.
- Reward modeling for video: VideoReward / Flow-DPO, UnifiedReward.
- Ad-specific rubrics: Springboards Creativity Benchmark, AdsQA, the Pitt Ads Dataset, "Decoding the Hook" for first-3s evaluation.
- Closed-loop quality assurance: Meta-Harness (Lee, Khattab, Finn et al.); Learning Beyond Gradients (Weng) on critique-and-revise loops over explicit policies.